
Remember how a major chunk of the internet was inaccessible thanks to errors that popped up on AWS’s S3 servers? Well, Amazon has finally completed its post-mortem of the problem and it appears that the main culprit behind the error was a simple typo.
In a note that was published by Amazon today, the company explained that members of the S3 team needed to take a small number of servers offline in order to conduct some debugging of the billing system. However, a typo found in the input command caused a larger set of servers to be taken offline than intended.
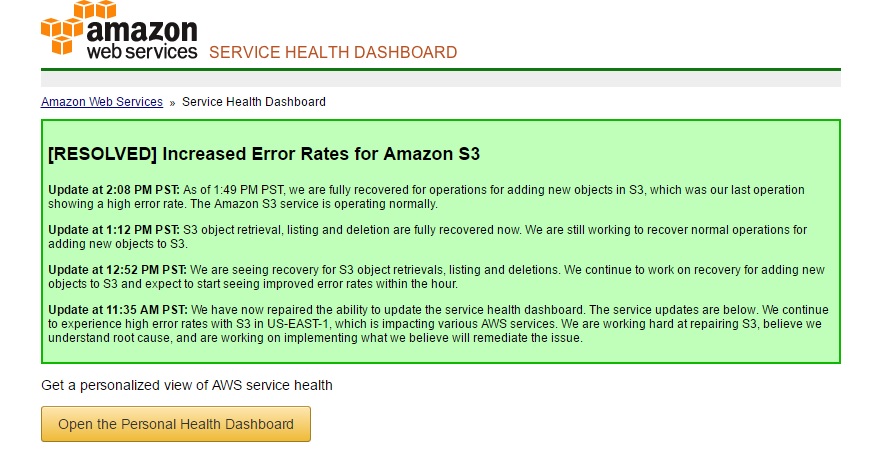
Said servers also happened to support two major S3 subsystems: one that manages metadata, and another that manages location information. With both subsystems offline, services that depend on it are unable to perform basic data retrieval and storage leaks. With a large chunk of S3 now offline, the system are forced to do a full restart. During the time it takes for that to happen, other parts of Amazon Web Services stopped as well.
Amazon admitted that the S3 system was unable to handle a massive restart and as such, the company will be making changes to the system in order for it to recover more quickly from future accidents like this. Additionally, the company will be installing new safety features into the system that would prevent engineers from removing capacity from S3 if it would take subsystems below a certain threshold.


